
Blog
A terrible idea: Using Random Forest for root cause analysis in manufacturing
Over the past years, our interactions with industry experts have revealed a significant trend for root cause analysis in manufacturing. As the data coverage in modern factories increases, we are observing a growing number of manufacturers who adopt “off-the-shelf” machine learning (ML) algorithms in favor of traditional correlation-based methods. Despite the initial promise of conventional ML algorithms, like Random Forests, this article demonstrates that they can provide seriously misleading conclusions.
Feature importance is the wrong proxy for root causes
Many manufacturers are trending towards the use of Random Forests for root cause analysis. There’s been an observable shift toward tree-based algorithms to understand the relationship between a set of production parameters and undesirable production outcomes. A popular method involves training a Random Forest to establish predictive relationships, and then utilizing “feature importance” to assess how strongly each production parameter (e.g., temperature) predicts a certain outcome of interest (e.g., quality losses). The key assumption here is that highly predictive parameters are also important for explaining the underlying production problems that need to be addressed. However, the core fallacy of this approach lies in the fact that Random Forests are designed for prediction tasks, which fundamentally differ from the objectives of root cause analysis in manufacturing.
So, why is the use of Random Forests for root cause analysis a bad idea? At its core, the issue is that predictive power should not be confused with causal effects. Root cause analysis aims to identify factors that significantly affect the financial bottom line. However, as we demonstrate in this article, the parameters deemed most predictive by a feature importance analysis don’t necessarily align with these critical factors. Moreover, a factory represents a structured flow of processes. Conventional ML algorithms neglect a factory’s process flow by simplifying it to mere tabular data. This oversimplification can have severe consequences where important causal relationships are entirely overlooked.
In the following, we’ll delve into the limitations of using Random Forests for root cause analysis. We’ll use two straightforward examples from a hypothetical cookie factory, which aim at uncovering the root causes of quality problems. In the first example, we demonstrate that Random Forests are sensitive to outliers and their feature importance overemphasizes the relevance of rare events. In the second example, we show that Random Forests are incapable of exploring root cause chains and thus fail to uncover the true sources of quality problems. Additionally, we’ll demonstrate how EthonAI’s graph-based algorithms effectively address these shortcomings.
The cookie factory
Let’s introduce a practical use-case for our analysis: a cookie factory. In the figure below, you’ll find the layout of this factory, from incoming goods to final quality control. The cookie factory is designed to produce orders in batches of 100 cookies each. While the overall setup is a simplification, it effectively captures the essence of a real-world production environment. Our focus here is to understand how various parameters interact and how they relate to the overall quality of the cookies. To this end, we’ll generate synthetic data based on two different scenarios.
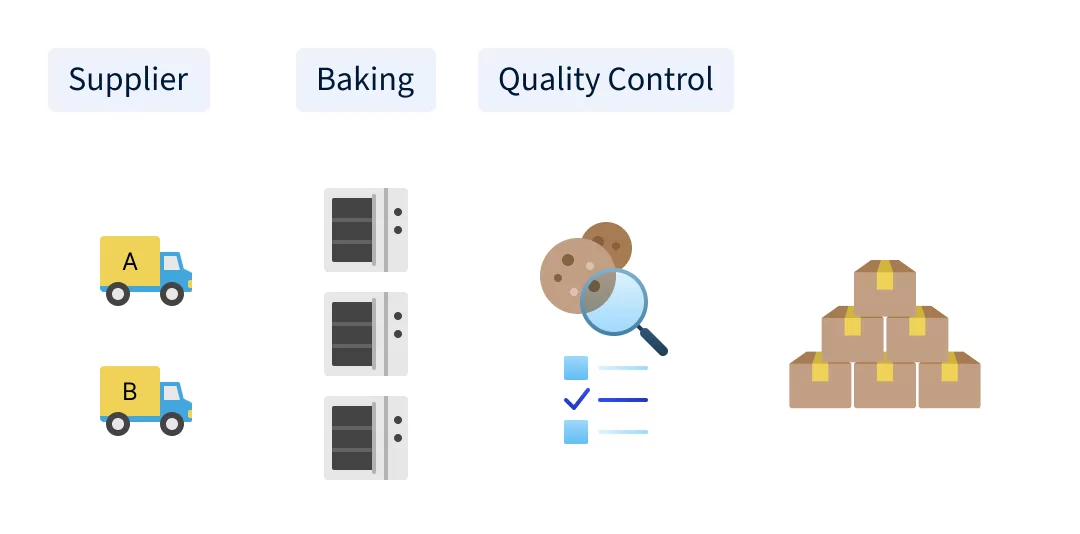
Our cookie factory’s process flow begins with the arrival of raw ingredients. Flour, sugar, butter, eggs, and baking powder are supplied by two different providers, labeled Supplier A and Supplier B. To maintain a standard in each batch, a production order of 100 cookies exclusively uses ingredients from one supplier. Though the ingredients are fundamentally the same, subtle variations between suppliers can influence the final product.
Next is the heart of the cookie factory – the baking process. Here, the ingredients are mixed to form a dough, which is then shaped into cookies. These cookies are baked in one of three identical ovens. Precise control of the baking environment is key, as even minor fluctuations in temperature or baking duration can significantly impact cookie quality. For every batch of cookies, we record specific details: the oven used (Oven_ID), the average temperature during baking, and the exact baking duration. These data points provide valuable insights into the production process.
The final stage in our factory is quality control, which is conducted by an automated visual inspection system. This system spots and rejects any defective cookies – be they broken or burnt. We’ll use “yield” as a quality metric. Yield is defined as the share of cookies in one production order that meet our quality standards and are ultimately delivered to the customer (e.g., if 95 out of 100 cookies pass quality control the yield equals to 95%).
In our subsequent analyses, we’ll dissect how production parameters like Supplier_ID, Oven_ID, Temperature, and Duration influence the quality of our cookies. Our goal is to explore the interplay of these parameters that determines why some cookies make the cut while others have to be thrown away.
For our upcoming examples, we’ll simulate production data from our cookie factory. For this, we will create synthetic data for our production parameters, namely the Supplier_ID, Oven_ID, Temperature, and Duration. Additionally, we have to establish a “ground-truth” formula that models the relationship between these parameters and the cookie quality. We model the quality of each cookie production batch based on the following two parameters: the Temperature and the Duration. We’ll use the following formula to simulate the yield for each production batch:

Here’s a breakdown of the above formula:
- The ideal baking temperature is set at 200° Celsius. Deviations from this temperature reduce the yield.
- Similarly, the ideal baking duration is 20 minutes. Any deviation from this time affects the yield negatively.
Let’s consider an illustrative example: Imagine a cookie batch is baked at 210° Celsius for 22 minutes in Oven-1 using ingredients from Supplier A. The yield calculation would be: 100 – 5 (Temperature deviation) – 5 (Duration deviation) = 90%. This means 90 cookies pass quality control and 10 cookies are thrown away. Note that the above formula represents the actual modeled relationships in our scenario, but is assumed to be unknown for our root cause analysis.
Scenario 1: Predictive modeling is not the right objective for root cause analysis
In this first scenario, we’ll expose a critical weakness of Random Forests: their tendency to overfit outliers and, thus, to overestimate the relevance of rare events. While Random Forests can quantify predictive power via feature importance, they ignore the frequency and magnitude of each parameter’s financial impact. Our subsequent example with simulated data sheds light on this critical problem.
Setting the Simulation Scenario for Scenario 1
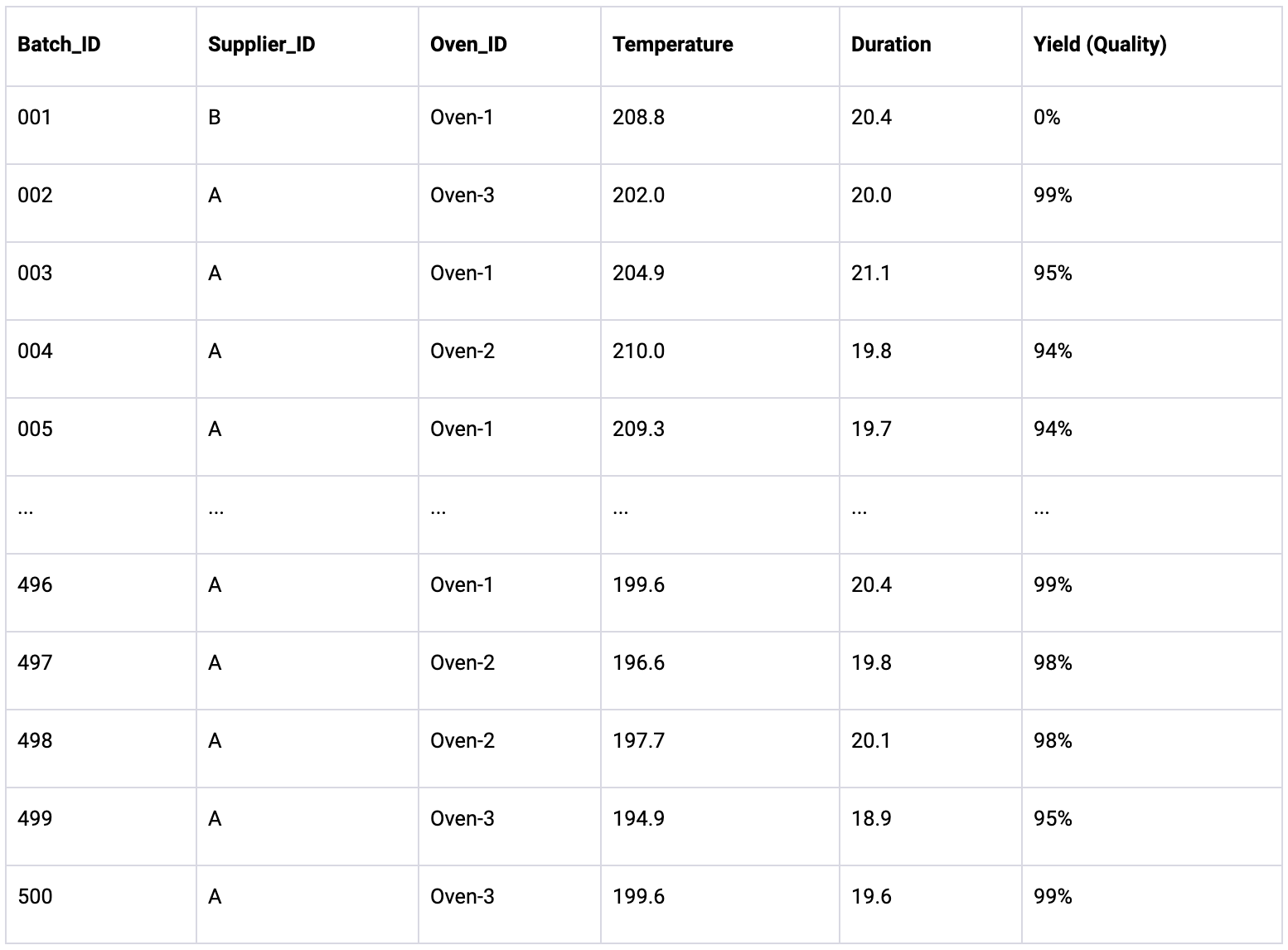
We start by simulating a dataset with 500 production batches based on our ground-truth quality formula. In order to demonstrate that Random Forests are very sensitive to outliers, we introduce a significant data imbalance into our dataset: only the first batch uses raw ingredients from Supplier B, whereas the remaining 499 batches use ingredients from Supplier A. Furthermore, we assume that after the first batch was produced, one of the cookie factory’s employees accidentally dropped the entire batch to the floor, resulting in all the cookies breaking. Consequently, the first batch of cookies has a yield of 0%. This exaggerated incident is specifically designed to highlight Random Forests’ sensitivity to outlier events. Such outlier events happen rarely, and hence, over an extended period, they impact the quality only minimally. Moreover, since those outlier events are often due to human error, they may not be avoidable. As such, a good root cause analysis should not identify the outlier event or anything that is spuriously correlated with it.
Here’s a snapshot of the simulated dataset:
Root cause analysis with Random Forest and feature importance
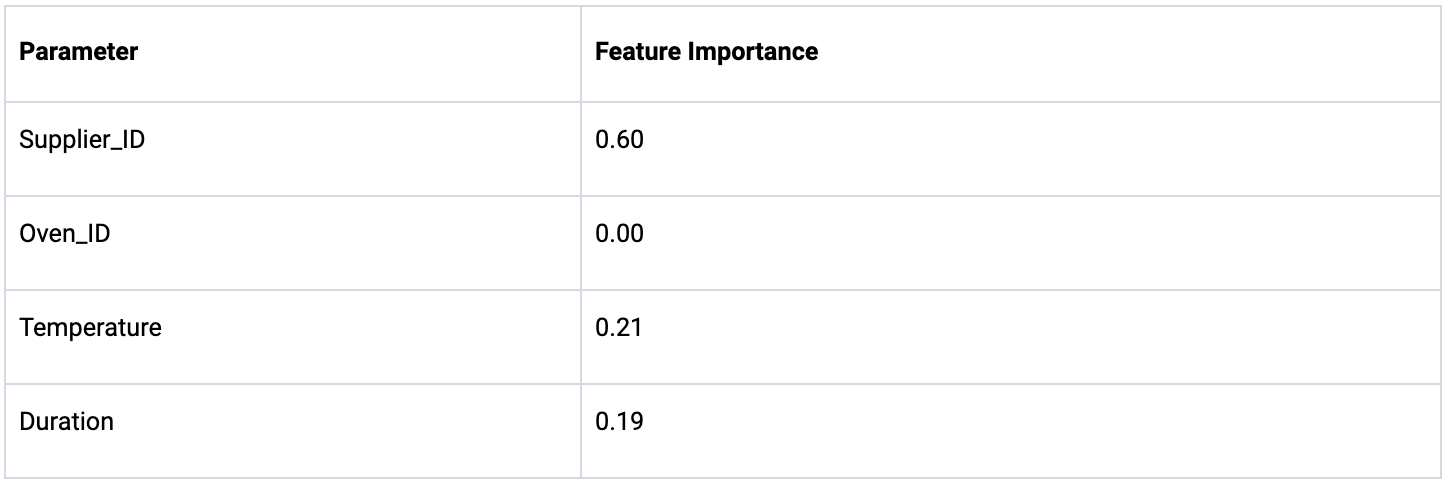
We now use a Random Forest model to analyze the above dataset of 500 production batches. The model is trained to predict the yield based on four parameters: Supplier_ID, Oven_ID, Temperature, and Duration. Subsequently, we compute the feature importance of each parameter to identify which of them is the most predictive of the overall cookie yield.
The feature importance analysis identifies Supplier_ID as the most predictive parameter with a score of 0.60, followed by Temperature at 0.21, and Duration at 0.19. This ranking suggests that the supplier has the largest effect on cookie quality. Knowing how the data was generated, which is that the Supplier_ID is unrelated to the quality, we can immediately establish that this finding is wrong. In fact, the Random Forest attributes the Supplier_ID with high feature importance, because Supplier B was only used once for the first production batch (i.e., Batch_ID = 001), which has a yield of 0%, because it was accidentally dropped to the floor. Hence, the Random Forest erroneously placed high importance on this outlier event and identified the Supplier_ID to be the reason for this event, which is also incorrect.
Root cause analysis with EthonAI Analyst
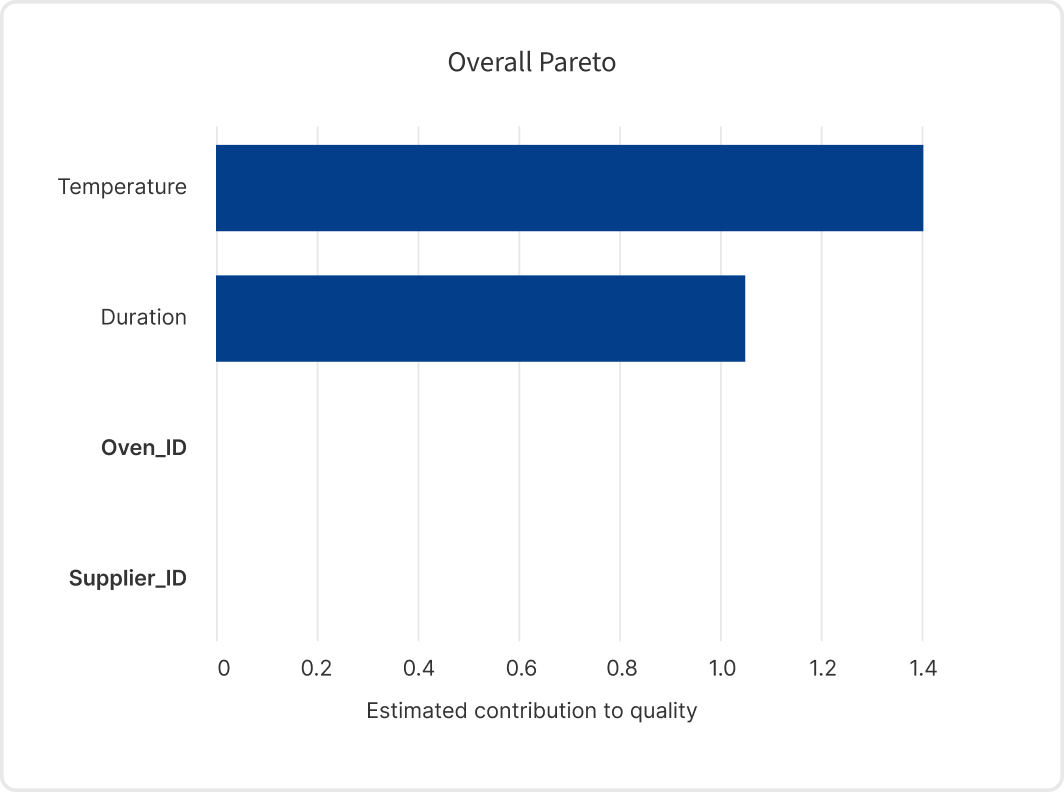
We now apply the EthonAI Analyst software to conduct the same analysis for the first scenario. The EthonAI Analyst makes use of graph-based algorithms that have been particularly designed for root cause analysis in manufacturing. One of their key abilities is to account for the frequency of root causes, which identifies the production problems that truly matter for cost reduction.
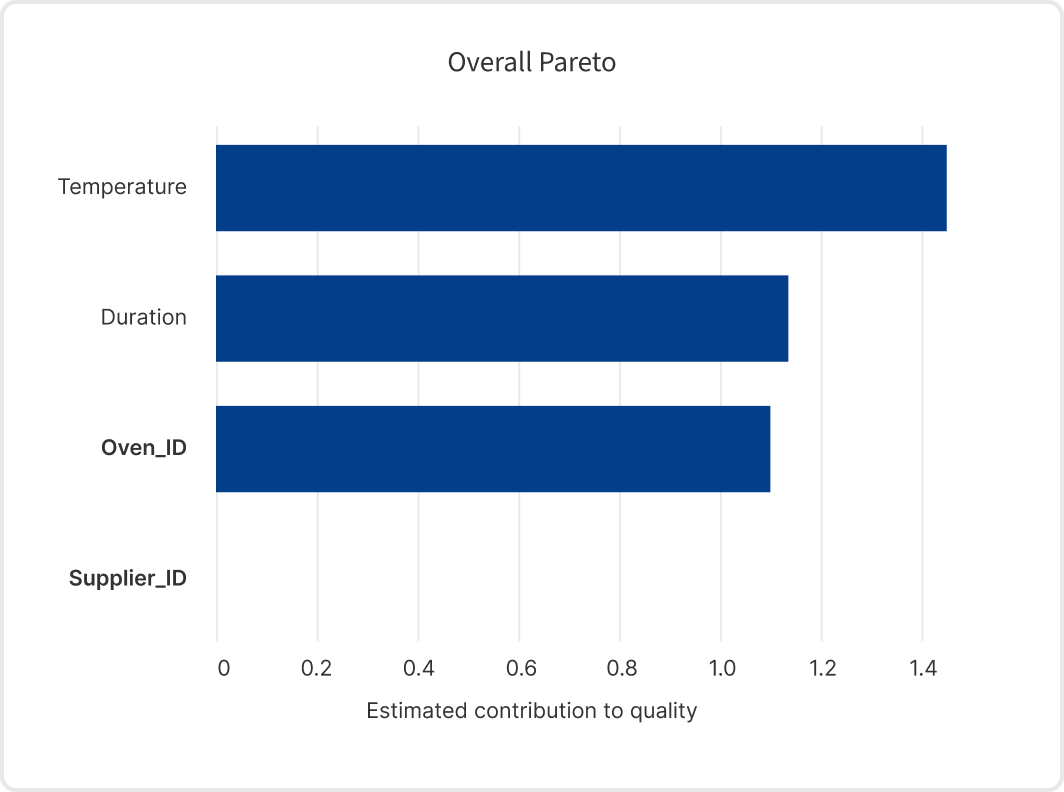
Upon analyzing the data, the EthonAI Analyst presents a ranking of parameters based on their impact. It attributes high importance to Temperature and Duration, thereby recognizing these as the primary factors affecting cookie quality. Notably, the Supplier_ID is deemed inconsequential because the EthonAI Analyst effectively avoids the overfitting issues encountered with the Random Forest. This demonstrates the importance of accounting for both the frequency and the impact of root causes to effectively identify the parameters that have a consistent effect on quality.
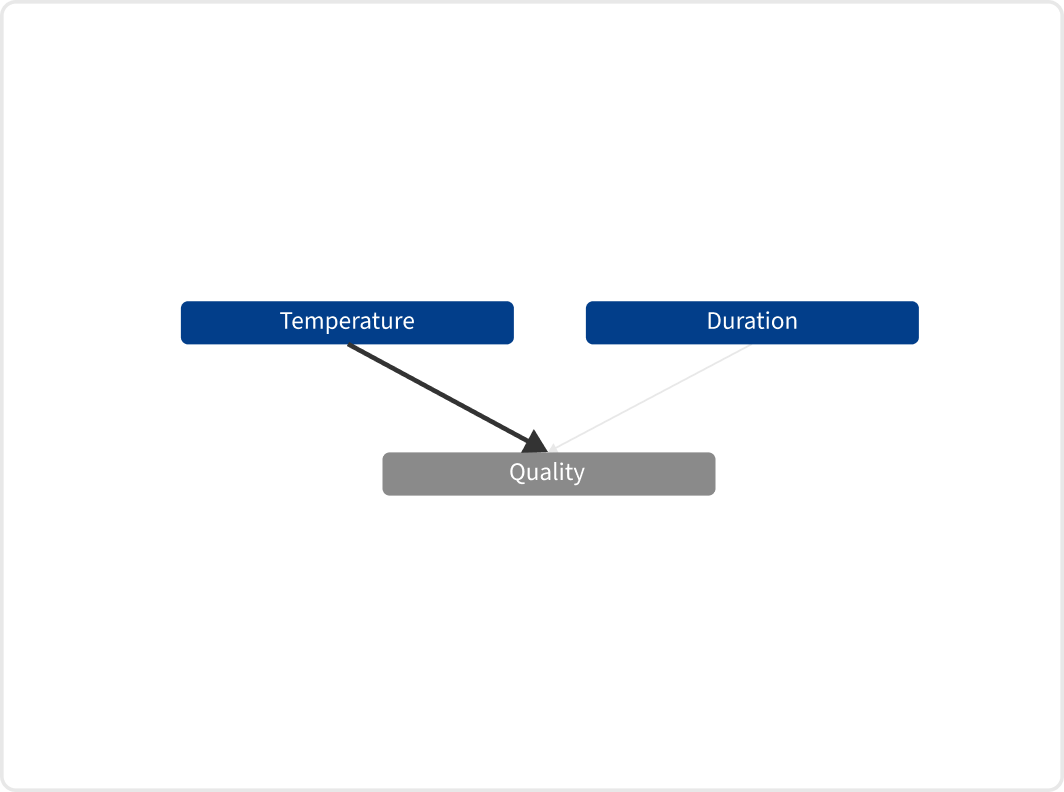
Scenario 2: A factory cannot be represented by tabular data
In our second scenario, we show how the inability of Random Forests to accurately model process flows leads to missed opportunities for quality improvement. Random Forests operate fundamentally different to the established problem-solving methodologies that are used in manufacturing. For example, the 5-Why method involves a procedure of repeatedly asking “why” to trace a root cause to its origin. However, since conventional ML algorithms treat factories as static data tables rather than dynamic processes, they fail to employ the backtracking logic that is essential for analyzing root cause chains.
Setting the Simulation Scenario for Scenario 2
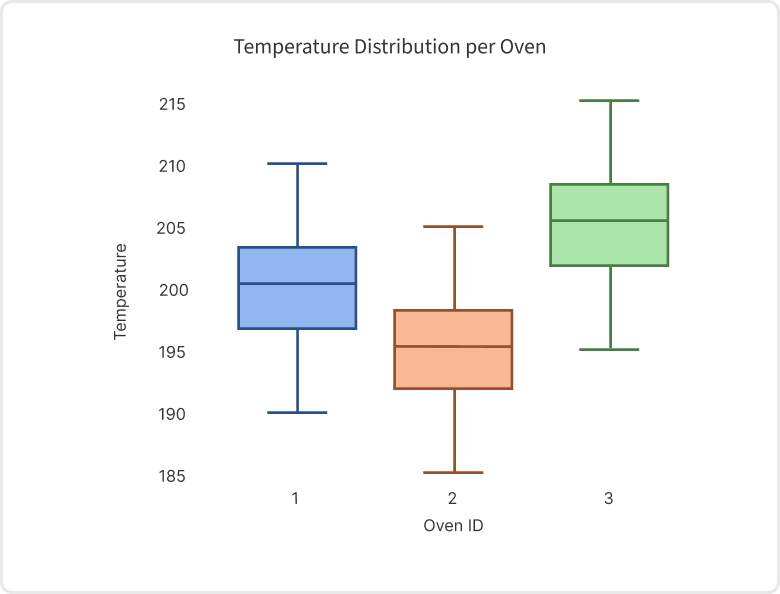
We again simulate a dataset of 500 production batches with the same quality formula as before. Unlike the previous scenario, both suppliers A and B now supply a similar amount of ingredients across production orders. To illustrate how Random Forests fail to account for ripple effects throughout a factory, we add an additional complexity to the dataset. Specifically, we introduce a calibration issue in the baking process, which affects the temperature measurements of Oven-1, Oven-2, and Oven-3. This creates a root cause chain where the Oven_ID indirectly affects the yield by influencing the temperature. Below we visualize the temperature distributions across the different ovens, which show that Oven-2 and Oven-3 deviate more from the optimal temperature of 200° Celsius than Oven-1.
Root cause analysis with Random Forest and feature importance
We again use a Random Forest to analyze the new dataset of 500 production batches. As before, the model is trained on Supplier_ID, Oven_ID, Temperature, and Duration to predict the resulting yield. We then compute the feature importance to determine the most predictive production parameters.
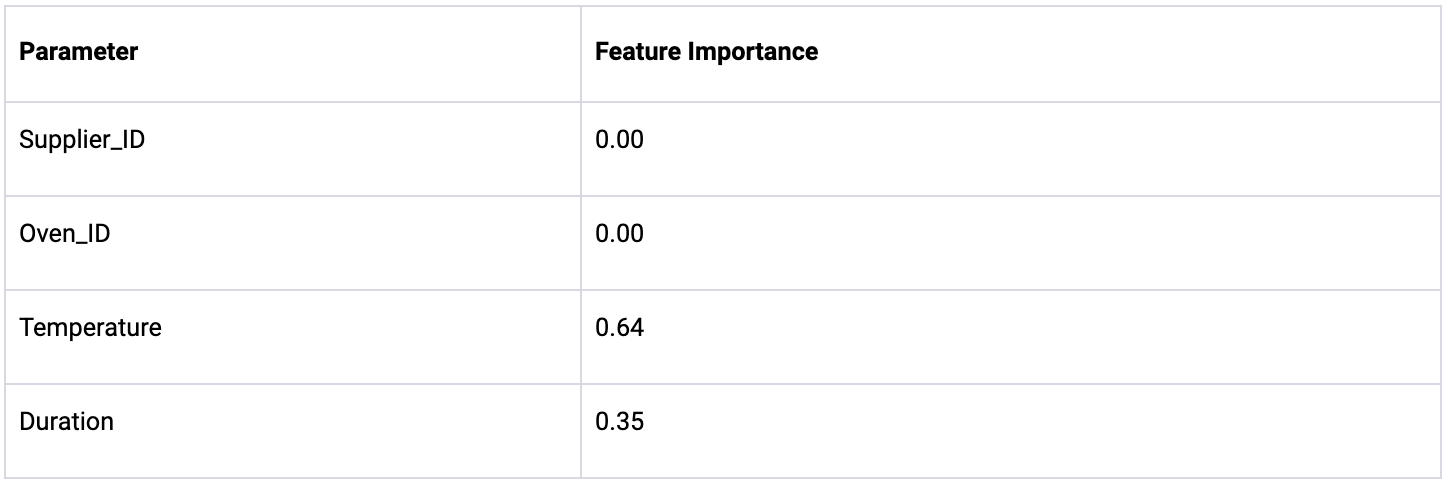
The model identifies Temperature as the most significant parameter with a feature importance of 0.64, followed by Duration at 0.35. Notably, both Oven_ID and Supplier_ID have a feature importance of 0.00, implying they have no impact on the yield. However, since we know the underlying data generation process, we can confirm that the lack of feature importance attributed to Oven_ID is incorrect. This error occurs because the model fails to capture how Oven_ID indirectly affects yield through the Temperature parameter.
Root cause analysis with EthonAI Analyst
We now repeat the analysis for the second scenario with the EthonAI Analyst software. Unlike Random Forests, the EthonAI Analyst employs our proprietary algorithms that capture process flows by modeling them as a causal graph. This helps identifying complex root cause chains and tracking production problems back to their actual root cause.
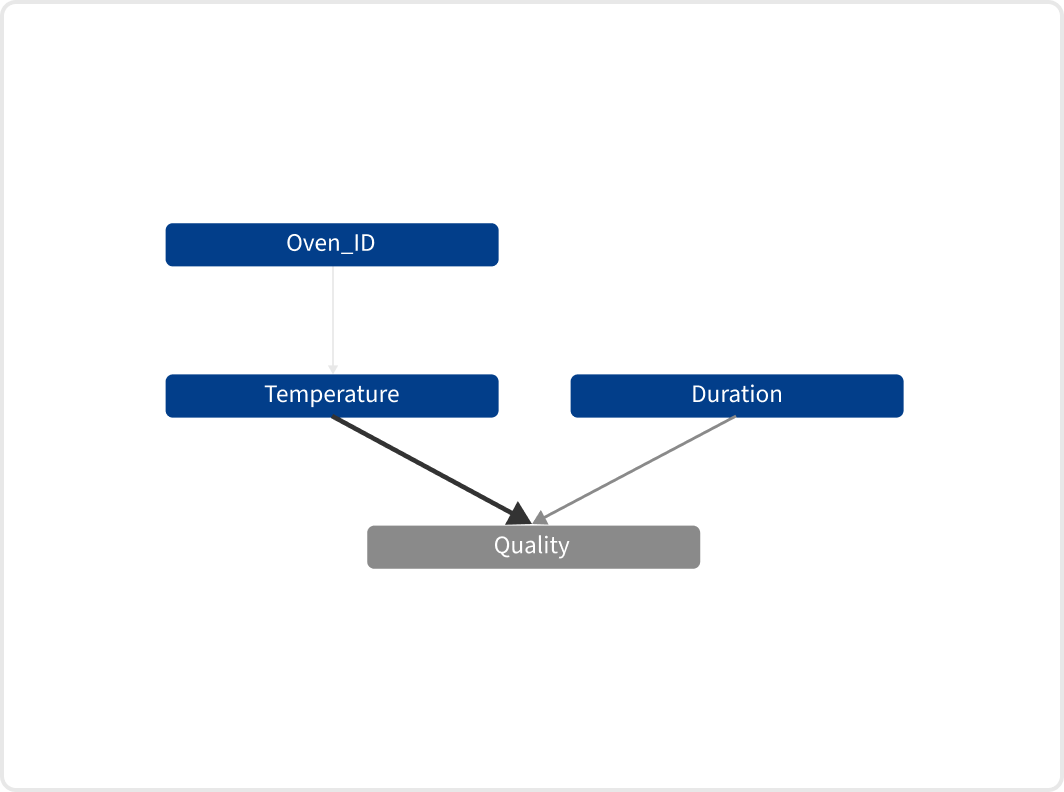
Examining the results from the EthonAI Analyst presents a contrasting view to the Random Forest’s results. Like the Random Forest, it identifies Temperature and Duration as critical parameters. However, the EthonAI Analyst correctly recognizes Oven_ID as a significant parameter too. This is clearly illustrated in the extracted graph, which reveals Oven_ID’s indirect influence on yield through the Temperature parameter.
Conclusion
Random forests have become popular for root cause analysis in manufacturing. However, our article demonstrates they have serious limitations. In two simple scenarios with just four production parameters, we demonstrate that Random Forests fail to accurately identify the root causes of simulated quality losses. The first scenario showed their tendency to confuse predictive power with financial impact. The second scenario illustrated their inability to trace chains of root causes. This raises an important concern: Are conventional ML algorithms like Random Forests reliable enough when it comes to analyzing hundreds of production parameters in complex factories? Our findings suggest they are not.
Moving forward, we advocate for the adoption of graph-based algorithms. Compared to conventional ML algorithms, they provide more accurate insights and identify the problems that truly hit the bottom line. We hope this article inspires professionals to pursue more robust and effective root cause analysis in their factories. If you’re intrigued and want to explore the capabilities of graph-based algorithms, we encourage you to book a demo and see the difference for yourself.
