Industrial anomaly detection: Using only defect-free images to train your inspection model
Introduction
This article explains why it is important to use an inspection approach that does not require images of defective products in its training set, and what kind of algorithm is suited in practice.
Requirements for visual quality inspection
Industrial anomaly detection in quality inspection tasks aims to use algorithms that automatically detect defective products. It helps manufacturers achieve high quality standards and reduce rework.
This article focuses on industrial anomaly detection with image data. Modern machine learning algorithms can process this data to decide whether a product in an image is defective. To train such algorithms, a dataset of examplary images is needed.
An important feasibility criterion for manufacturers is the way these training datasets need to be compiled. For instance, some naive algorithms require large datasets to work reliably (around one thousand images or more for each product variant). This is expensive and often infeasible in practice. That’s why we only consider so-called few-shot algorithms that work reliably with a low number of examples, specifically much less than one hundred images.
Another aspect that distinguishes algorithms is whether examples of defective products are needed. Here, we can broadly distinguish two classes of algorithms: (1) “generative algorithms” that can learn from just normal (or defect-free) products, and (2) “discriminative algorithms” that require normal and anomalous (or defective) images.
This is an important distinction for two reasons. First, anomalies are often rare, and when the manufacturing of new product variants starts up, no defective data is available for training. Secondly, by definition "anomalous" is everything that is not normal, which makes it practically impossible to cover all possible anomalies with sufficient training data. The latter is the more important argument, so let’s look at it in more detail.

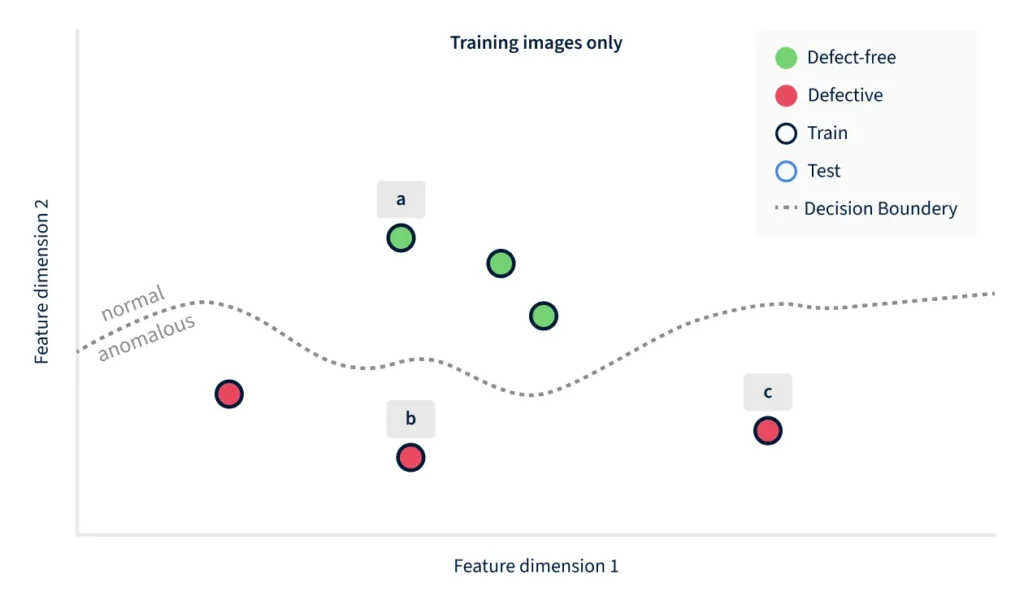
Figure 1 illustrates this. The single example in (a) should already give you a good impression of the concept of "normal." By contrast, the training images in (b) and (c) are by no means sufficient to define the concept for “anomalous” (e.g., other defect types such as discolorizations or misplacements are not represented).
Choosing the right type of algorithm
To better understand how discriminative and generative models differ when applied to anomaly detection, we use the PCB example in Figure 1 to construct a hypothetical scenario. For the sake of simplicity, a discriminative algorithm can be thought of as a decision boundary in a high-dimensional feature space. Each image becomes a point in that space, and lies either on the "normal" or the "anomalous" side of the boundary. Figure 2 simplifies this even further, down to a two-dimensional feature space. Such algorithms look at the training data of the two classes (normal and anomalous) and try to extract discriminating features when constructing the decision boundary. As such, these algorithms are likely not robust on unseen and novel defect types.
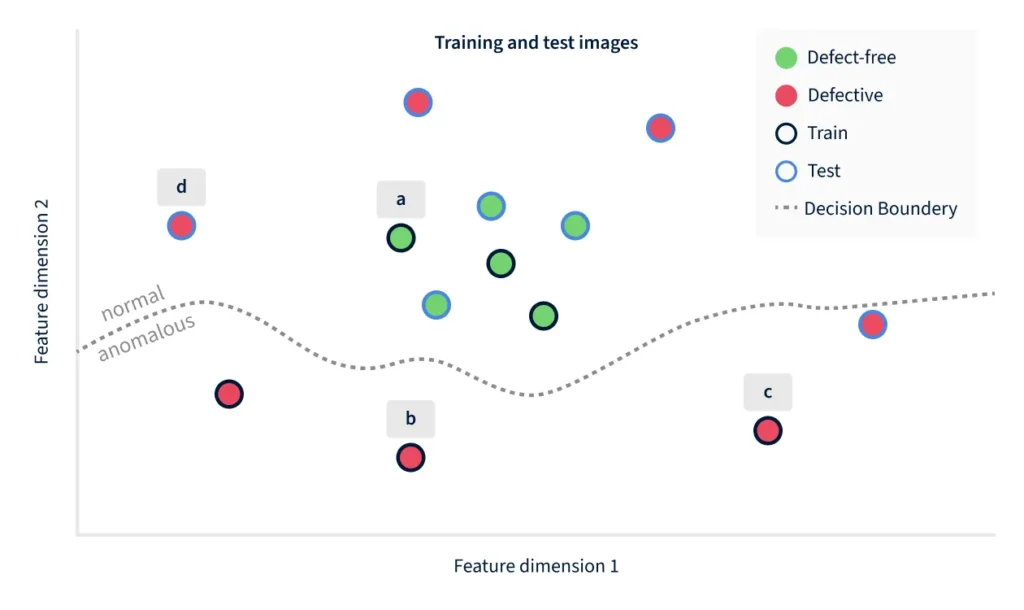
To see how a discriminative algorithm fails in practice, recall that anomalous is everything that is not normal, and consider that normal images tend to occupy only a small volume in the wide feature space. By contrast, the surrounding space of anomalous images is vast. It is thus very unlikely to gather sufficiently numerous and different examples of such images for training.
In the example of Figure 2, the training images (with a black outline) happen to cover just the lower part of the space, and the resulting decision boundary is good at making that distinction. But it does not encode the fact that defective products can also lie further above, to the right, or to the left – which is where the unseen example 1(d) happens to lie.
Figure 2 illustrates the problem with discriminative models, when defect types are not part of the training set. The decision boundary may end up working well on the training data, but previously unseen defects can easily end up on the "normal" side of the boundary. Concretely in this example, the image 1(d) happens to be closer in feature space to the non-defective images than the defective images 1(b) and 1(c).
For this reason, we strongly advocate to use algorithms that focus on learning the concept of normality instead, and can thus be trained solely from normal images. Such algorithms can also benefit from defective images in their training set, in order to improve robustness to specific types of defects, but crucially, they do not require them. Using ML terminology, we seek industrial anomaly detection algorithms that explain how normal data is generated, as opposed to discriminating normal from anomalous images. Such models can represent the generative process behind normal data. This can be used to judge whether or not an image could have been created via this generative process. If not, then the image is anomalous.
Conclusion
The Inspector offered by EthonAI provides a state-of-the-art solution for manufacturers to the problem of visual inspection. The EthonAI Inspector performs anomaly detection with generative algorithms that can be trained with just a few defect-free images. This is a great advantage in manufacturing environments, where gathering images is expensive, especially if examples of defects need to be in the training data. In addition, the nature of the algorithms that we deploy are robust towards unseen defects, as outlined above. We constantly observe that customers can uncover new defect types in their manufacturing process that they were unaware of before. This significantly improves the quality assurance process as a whole.
Generative modeling (or generative AI) has seen tremendous successes in the past years. It is expected that the usage of such models will continue to grow in manufacturing and help set new quality standards. Most real-world scenarios require knowledge on how normal images are generated, including factors of allowed variations such as lighting and position. EthonAI will continue to push the limits of such algorithms, and help you ensure that you don't ship defective products to your customers.

Christian Henning is lead research scientist for EthonAI's visual inspection solutions. He holds a PhD from ETH Zurich, where he conducted research on continual learning in AI. Christian's research has been published in leading computer science outlets, including NeurIPS and ICLR.
